If you build a state machine on top of a relational database you can abstract concurrency problems away from your business logic and allow developers to write safe-by-default code without dealing with concurrency concerns. This post explains how to build a library that offers those protections, and how they work under-the-hood.

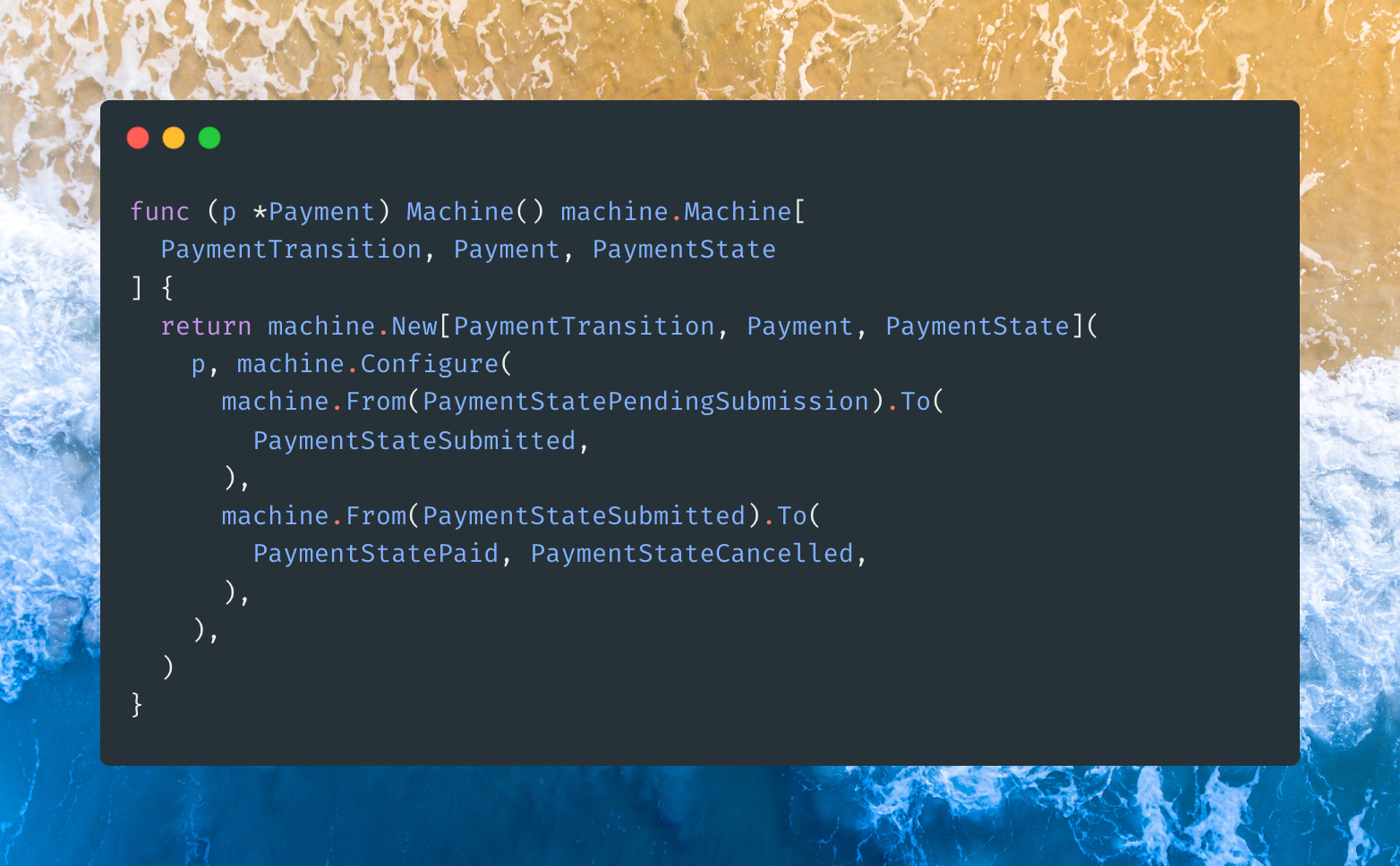
Is it just me or is this a nightmare implementation in terms of software maintenance and operations? Each state transition requires a database trip, state machine transitions are determined at runtime and there’s no simple way to reproduce them locally, and in the case of the state machine database going down the system simply cannot work.
What exactly is the selling point of this approach?
It’s long running, so you want a database so you can store your state. If you’re storing state, locking it into a state machine makes sense.
I do agree with some of the commenters that making it closer to an event source design would make more sense still.
That’s besides the point. Of course that the most fitting way to represent a state machine is with a state machine. The point is that implementing the transition table in a database table creates many problems while apparently solving none.