Technically correct is the best kind of correct.
If you copy something you are not entitled to because of copyright, it’s copyright infringement.
With theft the originally owner loses what is stolen, with copyright infringement the owner only loses the license fee for 1 copy.
Not the same thing, and calling it theft is purely a propaganda term invented by the media industry.
It should also be noted that copyright laws usually have all sorts of exceptions for fair use such as satire, education, etc. Typically, keeping and even using a copy without permission is legally allowed under certain circumstances.
Just a word of caution. Even if you have a valid fair use claim they have to be adjudicated and the legal costs can get pricey. Worse if you’re found liable.
Check out Lawful Masses on YouTube for plenty of examples of copyright trolls using this as a bludgeon.
It’s just a fear tactic. If enough people self represented themselves individually the companies would die. You can’t draw blood from a stone… which the average consumer is basically close to. The recovery rate vs the lawsuit fees would destroy the entire legal system if people stood their ground.
Canada decided to have none of that. Downloading without keeping a copy (streaming) was basically thrown out as copyright infringement, the whole lost income idea was generally laughed at, and the final result was a maximum judgement of $500 for all non-commercial copyright infringement prior to the suit. Which basically would pay for about one hour of the plaintiff lawyer’s fees. We don’t get a lot of copyright suits like that in Canada any more.
I like to think of it as something similar to watching a football match from the other side of the fence. People who paid the ticket, are loyal fans. People who didn’t pay, but still want to see the match, probably aren’t even part of the target audience. Some of them might be, but that’s a small number.
So, when the football company says that they’ve lost the sales of x number of tickets, they are actually saying that if those people had enough money and if they cared enough, they might have paid this amount of money.
Right, so I suppose George Lucas was stealing from all the movies that inspired his work when he made Star Wars. Or when Mel Brooks made Space Balls, as a more blatant example
Mel Brooks’s works are protected under the Fair Use provisions for satire under the DMCA. Lucas never copied anything directly, but, if pressed, much of his work is “heavily inspired” by works in the public domain and/or could be argued to be “derivative works”, also covered by Fair Use provisions in the DMCA, although any claim of copyright violation would be pretty difficult to make in the first place.
not in any legally reasonable way, and certainly not by anyone who understands how AI (or, really, LLM models) work or what art is.
If it’s not redistributed copyrighted material, it’s not theft
but that’s exactly what OpenAI did-- they used distributed, copyrighted works, used them as training data, and spit out result, some of which even contained word-for-word repetitions of the author’s source material.
AI, unlike a human, cannot create unique works of art. it can old produce an algorithmically-derived malange of its source-data recomposited in novel forms, but nothing resembling the truly unique creative process of a living human. Sadly, too many people simply lack the ability to comprehend the difference.
it can old produce an algorithmically-derived malange of its source-data recomposited in novel forms
Right, it produces derivative data. Not copyrighted material.
By itself without any safeguards, it absolutely could output copyrighted data, (albeit probably not perfectly but for copyright purposes that’s irrelevant as long as it serves as a substitute). And any algorithms that do do that should be punished, but OpenAI’s models can’t do that.
Hammers aren’t bad because they can be used for bludgeoning, and if we have a hammer that somehow detects that it’s being used for murder and then evaporates, calling it bad is even more ridiculous.
Some safeguards have been added which curtail certain direct misbehavior, but it is still capable - by your own admission - of doing it. And it still profits from the unlicensed use of copyrighted works by using such material for its training data. Because what it is producing is not a new and unique creative work, it is a composite of copyrighted work. That is not the same thing.
And if you are comparing LLMs and hammers, you’re just proving how you fundamentally misunderstand what LLMs are and how they work. It’s a false equivalence.

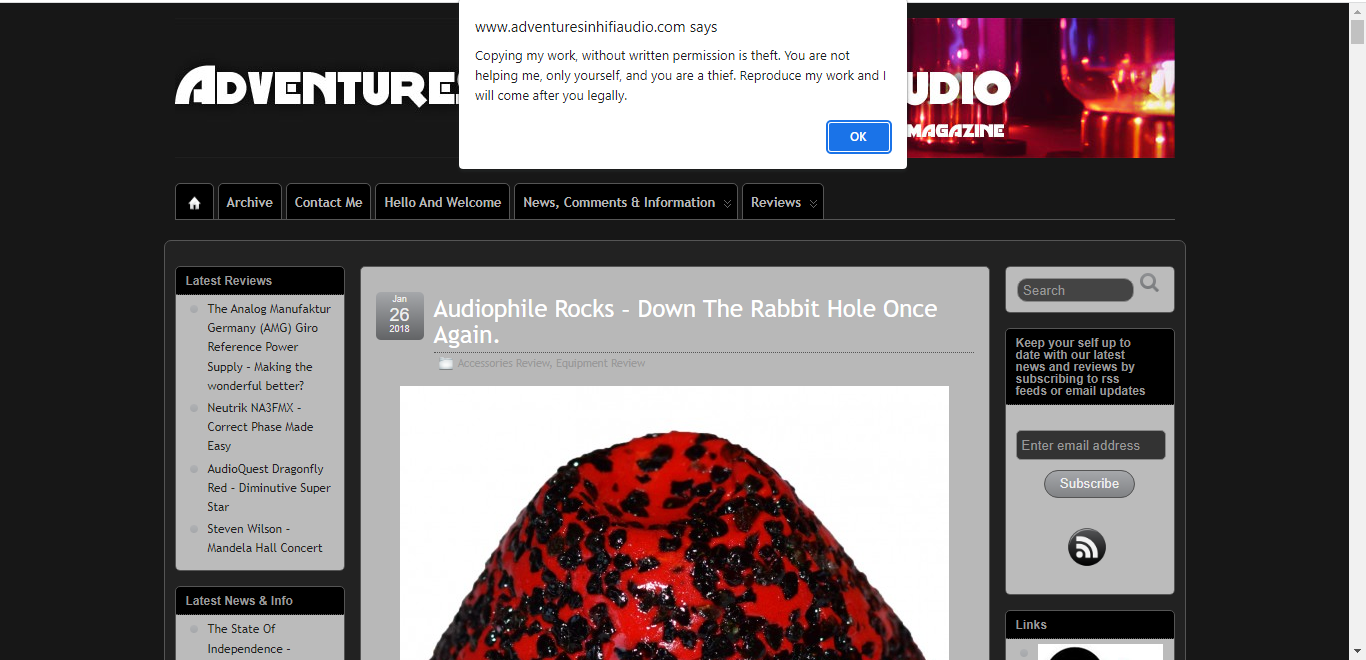{kind=link}
lol, copying isn’t theft. You already had to download a copy just to view it. That’s how websites work.
Technically correct is the best kind of correct.
If you copy something you are not entitled to because of copyright, it’s copyright infringement.
With theft the originally owner loses what is stolen, with copyright infringement the owner only loses the license fee for 1 copy.
Not the same thing, and calling it theft is purely a propaganda term invented by the media industry.
It should also be noted that copyright laws usually have all sorts of exceptions for fair use such as satire, education, etc. Typically, keeping and even using a copy without permission is legally allowed under certain circumstances.
Just a word of caution. Even if you have a valid fair use claim they have to be adjudicated and the legal costs can get pricey. Worse if you’re found liable.
Check out Lawful Masses on YouTube for plenty of examples of copyright trolls using this as a bludgeon.
It’s just a fear tactic. If enough people self represented themselves individually the companies would die. You can’t draw blood from a stone… which the average consumer is basically close to. The recovery rate vs the lawsuit fees would destroy the entire legal system if people stood their ground.
Canada decided to have none of that. Downloading without keeping a copy (streaming) was basically thrown out as copyright infringement, the whole lost income idea was generally laughed at, and the final result was a maximum judgement of $500 for all non-commercial copyright infringement prior to the suit. Which basically would pay for about one hour of the plaintiff lawyer’s fees. We don’t get a lot of copyright suits like that in Canada any more.
I like to think of it as something similar to watching a football match from the other side of the fence. People who paid the ticket, are loyal fans. People who didn’t pay, but still want to see the match, probably aren’t even part of the target audience. Some of them might be, but that’s a small number.
So, when the football company says that they’ve lost the sales of x number of tickets, they are actually saying that if those people had enough money and if they cared enough, they might have paid this amount of money.
Not a bad analogy. 👍
“Tools” -> “Page info” -> “Media” menu on Firefox - you can even see and save the images that the browser already downloaded.
or save page to download all loaded image assets from a page into a nice folder
Or there are extensions if you are lazy.
Yeah was going to recommend this it usually works pretty well
Try telling that to the AI hysterics
It’s different when you earn profit from another person’s work.
Right, so I suppose George Lucas was stealing from all the movies that inspired his work when he made Star Wars. Or when Mel Brooks made Space Balls, as a more blatant example
Mel Brooks’s works are protected under the Fair Use provisions for satire under the DMCA. Lucas never copied anything directly, but, if pressed, much of his work is “heavily inspired” by works in the public domain and/or could be argued to be “derivative works”, also covered by Fair Use provisions in the DMCA, although any claim of copyright violation would be pretty difficult to make in the first place.
And the same can be said about generative AI
If it’s not redistributed copyrighted material, it’s not theft
not in any legally reasonable way, and certainly not by anyone who understands how AI (or, really, LLM models) work or what art is.
but that’s exactly what OpenAI did-- they used distributed, copyrighted works, used them as training data, and spit out result, some of which even contained word-for-word repetitions of the author’s source material.
AI, unlike a human, cannot create unique works of art. it can old produce an algorithmically-derived malange of its source-data recomposited in novel forms, but nothing resembling the truly unique creative process of a living human. Sadly, too many people simply lack the ability to comprehend the difference.
Right, it produces derivative data. Not copyrighted material.
By itself without any safeguards, it absolutely could output copyrighted data, (albeit probably not perfectly but for copyright purposes that’s irrelevant as long as it serves as a substitute). And any algorithms that do do that should be punished, but OpenAI’s models can’t do that.
Hammers aren’t bad because they can be used for bludgeoning, and if we have a hammer that somehow detects that it’s being used for murder and then evaporates, calling it bad is even more ridiculous.
Some safeguards have been added which curtail certain direct misbehavior, but it is still capable - by your own admission - of doing it. And it still profits from the unlicensed use of copyrighted works by using such material for its training data. Because what it is producing is not a new and unique creative work, it is a composite of copyrighted work. That is not the same thing.
And if you are comparing LLMs and hammers, you’re just proving how you fundamentally misunderstand what LLMs are and how they work. It’s a false equivalence.